





關於 機器學習 的專業插圖
演算法運作大揭秘
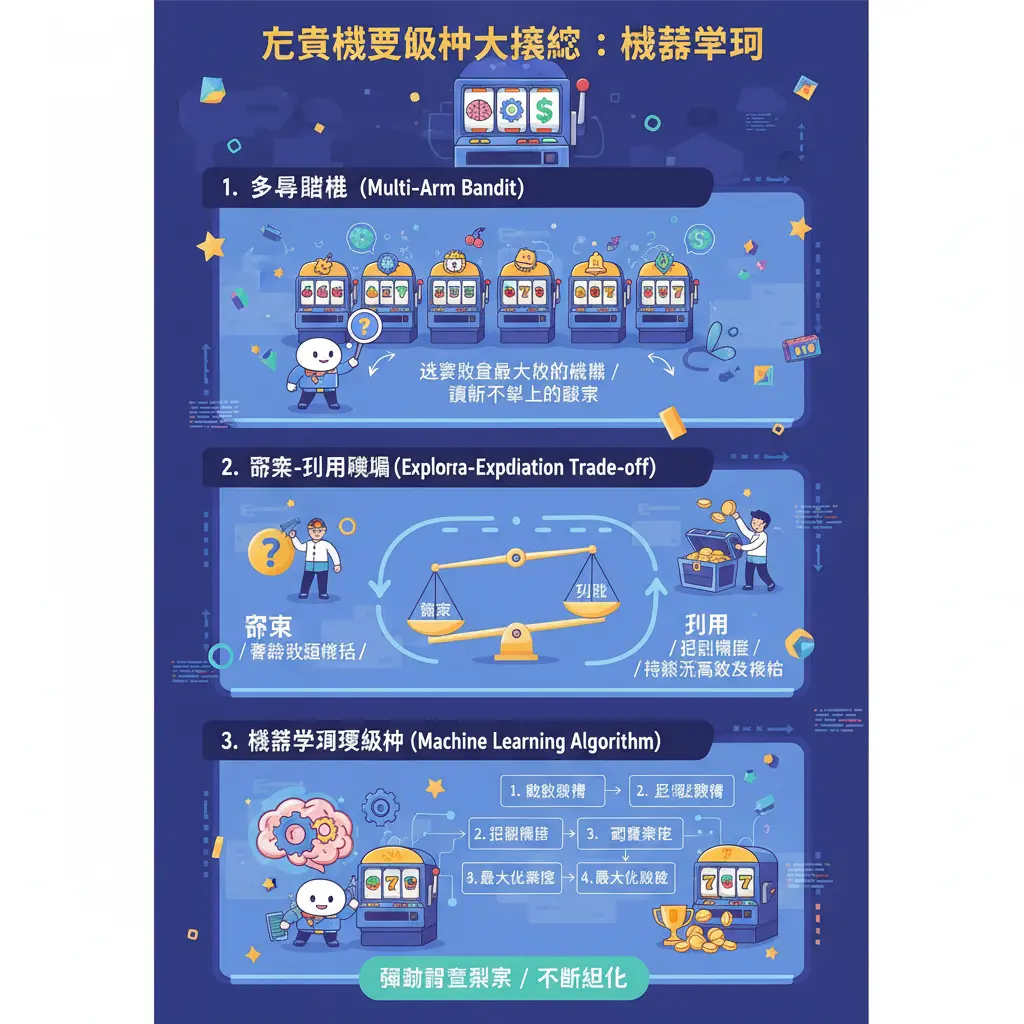
說到演算法運作大揭秘,我們得先拆解一個核心概念:多臂賭博機。這聽起來很學術,但其實它就是理解現代線上老虎機背後邏輯的鑰匙。想像你走進一個虛擬的賭場大廳,面對一排閃閃發光的線上老虎機,每台機器的玩家回報率和出獎模式都不同,但你手上的代幣有限。這時,你該如何決策制定,才能最大化收益呢?這就是經典的多臂老虎機問題本質——一個在資訊不完全下的資源分配與序貫決策問題。而驅動這一切的,正是一套複雜且不斷進化的演算法。
這套演算法的核心挑戰,在於探索-利用權衡。簡單來說,系統(或玩家)必須在「探索」未知選項(試試看另一台沒玩過的機器,可能報酬更高)和「利用」已知的最佳選項(繼續玩目前回報率最高的那台)之間做出抉擇。早期的系統可能依賴簡單的隨機數產生器來決定結果,強調純粹的隨機性以確保遊戲公平性。但如今,為了優化營運和玩家體驗(例如控制玩家回報率在一個精準的範圍),更先進的自適應演算法被廣泛應用。這些演算法會像一個聰明的管家,持續進行數據分析,根據海量的玩家行為數據,動態調整每台「虛擬機器」的出獎參數。
那麼,具體有哪些手臂選擇演算法在幕後工作呢?一個基礎的方法是貪婪演算法,也就是永遠選擇當前看起來平均回報最高的「手臂」。但這方法有個致命缺點:如果一開始運氣不好,它可能永遠發現不了真正最好的選項。因此,更常見的是它的改良版,例如「ε-貪婪」演算法。這個演算法大部分時間(1-ε 的機率)會選擇當前最佳選項(利用),但會保留一個小機率 ε 去隨機嘗試其他選項(探索)。這就像你雖然有最愛的老虎機遊戲,但偶爾還是會點開旁邊的新遊戲試試手氣,系統本身也在做類似的事。
然而,在當今高維數據的環境下,單純的統計方法已不夠用。這時,機器學習的強大能力就被引入了。強化學習正是處理這類序列決策問題的利器。你可以把老虎機演算法想像成一個自主學習的智能體:它每選擇一個「手臂」(例如,讓某個特定特徵的玩家進入某個獎勵回合),就會得到一個隨機獎勵(玩家的投注結果、遊玩時間等),目標是最大化長期的累積報酬。透過不斷地試錯和反饋,這個智能體會學會一套最佳策略,知道在什麼樣的遊戲情境、玩家模式下,該如何分配獎勵以達成營運目標(如維持玩家黏著度與控制總體支出)。
在機器學習的範疇內,除了強化學習,監督學習和無監督學習也扮演了輔助角色。監督學習可以用於預測玩家行為,例如根據歷史數據訓練模型,預測哪些玩家在特定獎勵觸發後更可能繼續遊玩。而無監督學習則能透過資料探勘進行玩家分群,將具有相似遊玩模式的玩家歸類,從而使演算法能對不同群體實施更精細的資源分配策略。這整個過程背後,離不開堅實的統計學與概率論基礎,所有決策都建立在數學模型之上,絕非憑空亂數決定。
更前沿的發展,甚至會用到人工神經網絡來處理極其複雜的非線性關係。例如,系統可以輸入數百個即時變數(玩家本次登入時間、近期勝率、餘額、遊玩遊戲種類等),透過神經網絡直接輸出一個動態的獎勵概率調整值。這種演算法設計讓系統的應變能力更強,也更難以被玩家單純的統計學方法破解。業界為了測試這些演算法的效果,經常進行大規模的A/B測試,將玩家隨機分組,體驗不同版本的演算法策略,並嚴格比較各組的累積報酬和關鍵績效指標,以持續最佳化整個系統。
總結來說,現代線上賭場的老虎機演算法,早已從單純的隨機數產生器,演化成一個融合了統計學習、機器學習(特別是強化學習)和資料探勘的智能決策制定系統。它不斷地在探索-利用權衡中尋找平衡,透過自適應演算法實時調整策略,其最終目的就是在確保遊戲公平性與合規性的外表下,達成平台設定的營運目標,無論是最大化營收,還是優化玩家的長期參與度。理解這背後的運作,你就能明白,你面對的不只是一台憑運氣的機器,而是一個高度複雜、動態調整的數學模型與最佳化工程。

關於 演算法 的專業插圖
搞懂機率與公平性
講到老虎機,大家最關心的就是「這遊戲到底公不公平?」以及「我到底有沒有機會贏?」這就必須深入搞懂機率與公平性背後的運作邏輯。現代線上老虎機的核心,早已不是單純靠機械轉輪或簡單的隨機數產生器,而是由一套複雜的演算法在驅動,這其中牽涉到大量的統計學與概率論原理。簡單來說,公平性建立在一個公開的參數上:玩家回報率。這個數字是由線上賭場預先設定,並經過獨立機構審核,代表長期下來,玩家投入的錢會有多少比例以獎金形式返還。但請注意,這是「長期統計」的結果,對單一玩家單次遊玩而言,每一次旋轉都是獨立的隨機獎勵,演算法確保的就是這種不可預測的隨機性。
那麼,這種隨機性和動態調整是怎麼做到的呢?這就要提到在機器學習領域中一個經典的數學模型——多臂賭博機問題。你可以把一台老虎機想像成有多個拉桿(手臂)的機器,每個拉桿代表一個可能帶來不同報酬的選擇(例如不同的遊戲功能、派彩模式或獎勵回合)。多臂老虎機問題本質上就是一個序貫決策問題:在有限的嘗試次數中,你要如何選擇拉桿,才能最大化收益,獲得最高的累積報酬?這個問題完美對應了遊戲設計者的挑戰:他們需要設計一套手臂選擇演算法,來動態分配資源(比如觸發獎勵的頻率),同時讓玩家感覺遊戲既有趣又充滿驚喜。這裡面最核心的思維就是探索-利用權衡。所謂「探索」,是指演算法會嘗試各種不同的選項,收集數據以了解哪個「手臂」的潛在回報更高;而「利用」則是指一旦發現某個手臂回報不錯,就傾向於多選擇它來獲取即時收益。一套好的自適應演算法會在這兩者之間取得動態平衡。
在實際的博彩環境中,遊戲開發者會運用強化學習來優化這套系統。強化學習是機器學習的一個分支,特別擅長處理這種序列決策問題。系統(也就是老虎機的後台大腦)會透過與環境(玩家行為)不斷互動,根據獲得的「獎勵」信號(例如玩家續玩意願、投注額變化)來調整策略。它可能會使用貪婪演算法作為基礎,但為了避免陷入局部最佳解,一定會加入隨機探索的機制。同時,為了處理更複雜的遊戲狀態和高維數據(例如玩家歷史行為、當前獎池大小、時間因素等),更先進的系統可能會引入人工神經網絡來進行特徵提取和決策預測,讓整個資源分配過程更加智能和難以被玩家簡單破解。
除了強化學習,資料探勘和統計學習也在確保「公平性」與「吸引力」之間扮演關鍵角色。開發者會分析海量的遊戲數據,透過A/B測試來驗證不同的演算法設計對玩家體驗和營收的影響。例如,微調免費遊戲的觸發概率,觀察哪種設定能讓玩家遊玩時間最長且滿意度最高。這一切的基礎都是數據分析和統計學,目的在於找到那個「甜蜜點」——既讓玩家有足夠的贏錢體驗(即使是小贏),從而感受到遊戲的公平與樂趣,又能確保平台在數學模型上的長期營利。所以,當你玩老虎機時,你面對的不只是一組冰冷的隨機數產生器,而是一個經過精密計算、不斷自我優化的決策制定系統。它保證了結果的隨機性與長期回報率的可預測性,這正是現代線上老虎機宣稱其遊戲公平性的科學依據。理解這一點,你就能明白,所謂的「策略」在長期且大量的旋轉面前,其影響微乎其微,因為系統的最佳化目標始終是維持那個預設的玩家回報率,並在過程中創造出令人沉迷的變化和期待感。